1. classes.dex 파일 (1)
APK 내부에는 classes.dex 파일명으로 Dalvik Executable File1이 존재한다. 이는 안드로이드에서는 실행 파일에 속하는 파일이다.
import mmap
fp = open('classes.dex', 'rb')
mm = mmap.mmap(fp.fileno(), 0, access=mmap.ACCESS_READ)
#---------------------------------------------------------------------
# TEST
#---------------------------------------------------------------------
print mm
[실행결과]
<mmap.mmap object at 0x032ECF20>
(1) 헤더
classes.dex 파일은 헤더의 크기가 0x70이다. 따라서 정상적인 classes.dex가 되기 위해서는 이 크기보다 커야 하며, 헤더에는 처음에 ‘dex’ 문자열이 온다.
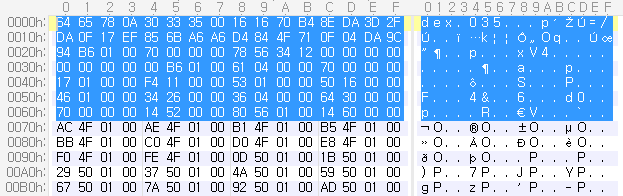
#---------------------------------------------------------------------
# isdex : dex 파일이 맞는지 체크
#---------------------------------------------------------------------
# 헤더가 'dex' 문자열로 시작하면서 최소 크기가 0x70 Byte 보다 커야 함
def isdex(mm) :
if mm[0:3] == 'dex' and len(mm) > 0x70 :
return True
return False
#---------------------------------------------------------------------
# TEST
#---------------------------------------------------------------------
print isdex(mm)
[실행결과]
True
isdex() 함수를 통해 classes.dex 파일이 맞다고 판단된다면 이제 헤더에 존재하는 중요 정보들을 분석하여 값을 알아내야 한다.
import struct
#-----------------------------------------------------------------
# header : dex 파일의 헤더를 파싱한다.
#-----------------------------------------------------------------
def header(mm) :
magic = mm[0:8]
checksum = struct.unpack('<L', mm[8:0xC])[0]
sa1 = mm[0xC:0x20]
file_size = struct.unpack('<L', mm[0x20:0x24])[0]
header_size = struct.unpack('<L', mm[0x24:0x28])[0]
endian_tag = struct.unpack('<L', mm[0x28:0x2C])[0]
link_size = struct.unpack('<L', mm[0x2C:0x30])[0]
link_off = struct.unpack('<L', mm[0x30:0x34])[0]
map_off = struct.unpack('<L', mm[0x34:0x38])[0]
string_ids_size = struct.unpack('<L', mm[0x38:0x3C])[0]
string_ids_off = struct.unpack('<L', mm[0x3C:0x40])[0]
type_ids_size = struct.unpack('<L', mm[0x40:0x44])[0]
type_ids_off = struct.unpack('<L', mm[0x44:0x48])[0]
proto_ids_size = struct.unpack('<L', mm[0x48:0x4C])[0]
proto_ids_off = struct.unpack('<L', mm[0x4C:0x50])[0]
field_ids_size = struct.unpack('<L', mm[0x50:0x54])[0]
field_ids_off = struct.unpack('<L', mm[0x54:0x58])[0]
method_ids_size = struct.unpack('<L', mm[0x58:0x5C])[0]
method_ids_off = struct.unpack('<L', mm[0x5C:0x60])[0]
class_defs_size = struct.unpack('<L', mm[0x60:0x64])[0]
class_defs_off = struct.unpack('<L', mm[0x64:0x68])[0]
data_size = struct.unpack('<L', mm[0x68:0x6C])[0]
data_off = struct.unpack('<L', mm[0x6C:0x70])[0]
hdr = {}
if len(mm) != file_size : # 헤더에 기록된 파일 크기 정보와 실제 파일의 크기가 다르면 분석을 종료한다.
return hdr
hdr['magic' ] = magic
hdr['checksum' ] = checksum
hdr['sa1' ] = sa1
hdr['file_size' ] = file_size
hdr['header_size' ] = header_size
hdr['endian_tag' ] = endian_tag
hdr['link_size' ] = link_size
hdr['link_off' ] = link_off
hdr['map_off' ] = map_off
hdr['string_ids_size'] = string_ids_size
hdr['string_ids_off' ] = string_ids_off
hdr['type_ids_size' ] = type_ids_size
hdr['type_ids_off' ] = type_ids_off
hdr['proto_ids_size' ] = proto_ids_size
hdr['proto_ids_off' ] = proto_ids_off
hdr['field_ids_size' ] = field_ids_size
hdr['field_ids_off' ] = field_ids_off
hdr['method_ids_size'] = method_ids_size
hdr['method_ids_off' ] = method_ids_off
hdr['class_defs_size'] = class_defs_size
hdr['class_defs_off' ] = class_defs_off
hdr['data_size' ] = data_size
hdr['data_off' ] = data_off
return hdr
#---------------------------------------------------------------------
# TEST
#---------------------------------------------------------------------
hdr = header(mm)
print hdr
[실행결과]
{'type_ids_size': 279, 'string_ids_off': 112, 'file_size': 112276,
'type_ids_off': 4596, 'field_ids_off': 9780, 'data_off': 24596,
'method_ids_off': 12388, 'data_size': 87680, 'map_off': 112128,
'field_ids_size': 326, 'method_ids_size': 1078, 'proto_ids_off': 5712,
'header_size': 112, 'sa1': '\x8e\xda=/\xda\x0f\x17\xef\x85k\xa6\xa6
\xd4\x84Oq\x0f\x04\xda\x9c', 'endian_tag': 305419896,
'string_ids_size': 1121, 'magic': 'dex\n035\x00', 'link_size': 0,
'checksum': 3027244566L, 'link_off': 0, 'class_defs_off': 21012,
'class_defs_size': 112, 'proto_ids_size': 339}
(2) String IDs
classes.dex에서는 문자열을 전체를 하나로 관리하고 있다. 제일 먼저 이 문자열이 존재하는 위치와 개수는 헤더 정보에서 확인할 수 있다.
print hdr['string_ids_size'] # 전체 문자열 개수
print hex(hdr['string_ids_off']) # 전체 문자열의 시작 위치
[실행결과]
1121
0x70
전체 문자열의 시작 위치로 이동하면 4Byte씩 1121개의 각 문자열의 위치 값이 아래 그림처럼 저장되어 있다.

size = hdr['string_ids_size'] # 전체 문자열 개수
off = hdr['string_ids_off'] # 전체 문자열의 시작 위치
print hex(off)
# 전체 문자열의 시작 위치에서 4Byte를 읽어서 출력한다. (첫번째 문자열의 시작 위치)
string_off = struct.unpack('<L', mm[off:off+4])[0]
print hex(string_off)
[실행결과]
0x70
0x14fac
문자열이 존재하는 위치를 확인해보면 1Byte는 문자열의 NULL을 제외한 문자열이 길이가 저장되어 있으며, 바로 이어서 실제 문자열이 등장한다.

위 그림에서 보면, 문자열의 길이는 0이며, 실제 문자열은 없고 뒤에 NULL이 존재함을 보여주고 있다. 위 내용에서 실제 문자열을 확인할 수 없으니, 5번째 문자열을 시작 위치 값을 확인해보자.
size = hdr['string_ids_size'] # 전체 문자열 개수
off = hdr['string_ids_off'] # 전체 문자열의 시작 위치
off = off + (4*5) # 4Byte씩 각 문자열의 위치 정보가 있으므로 6번째 문자열의 위치정보를 얻는다.
print hex(off)
# 전체 문자열의 시작 위치에서 4Byte를 읽어서 출력한다. (첫번째 문자열의 시작 위치)
string_off = struct.unpack('<L', mm[off:off+4])[0]
print hex(string_off)
[실행결과]
0x84
0x14fc0
5번째 문자열의 정보가 저장되어 있는 0x14fc0에 가면 다음의 정보를 확인할 수 있다.

첫 1Byte인 0xE는 NULL을 제외한 문자열의 길이가 14Byte임을 의미하며, 연이어 14Byte 값이 ‘ Destroying: ‘이 저장되어 있다.
string_len = ord(mm[string_off]) # 문자열의 길이
string_val = mm[string_off+1:string_off+1+string_len] # 문자열 추출
print string_len
print string_val
[실행결과]
14
Destroying:
그렇다면 전체 문자열을 추출하는 함수를 아래와 같이 만들 수 있다.
#---------------------------------------------------------------------
# string_id_list : dex 파일의 문자열 리스트를 추출한다.
#---------------------------------------------------------------------
def string_id_list(mm, hdr) :
string_id = [] # 전체 문자열을 담을 리스트
string_ids_size = hdr['string_ids_size']
string_ids_off = hdr['string_ids_off' ]
for i in range(string_ids_size) :
off = struct.unpack('<L', mm[string_ids_off+(i*4):string_ids_off+(i*4)+4])[0]
c_size = ord(mm[off])
c_char = mm[off+1:off+1+c_size]
string_id.append(c_char)
return string_id
#---------------------------------------------------------------------
# TEST
#---------------------------------------------------------------------
string_ids = string_id_list(mm, hdr)
# 전체 문자열 출력하기
for i in range(len(string_ids)) :
print '[%4d] %s' % (i, string_ids[i])
[실행결과]
[ 0]
[ 1]
[ 2]
[ 3]
[ 4] #
[ 5] Destroying:
[ 6] Finished Retaining:
[ 7] Op #
[ 8] Reseting:
(중간 생략)
[1115] zxl---NetChangeReceiver---url error---
[1116] zxl---NetWorkManager---connect error---
[1117] }
[1118] }}
[1119] �밭퍡��
[1120] 湲곕낯 �ㅼ젙��蹂듭썝, �대�
2. 결론
classes.dex 파일의 가장 기본인 헤더와 String 정보에 대해서 살펴보았다. 다음 편에서는 Type과 Proto 정보 추출에 대해서 살펴보도록 한다.
3. 참조
-
Dalvik Executable Format: https://source.android.com/devices/tech/dalvik/dex-format ↩