1. 분석 목적
NTFS 시스템의 특징을 이해하여 데이터 복제 및 복원을 가능하게 한다. 그리고 이를 확인 하기 위해 사용한 프로그램이나 함수들을 설명한다.
2. NTFS File System
NTFS 파일 시스템은 Windows NT에서 최초로 지원된 파일 시스템으로, FAT를 대체하기 위해 새롭게 개발된 파일 시스템이다. NTFS는 New Technology File System의 준말인데, 93년 7월 윈도우 NT 3.1에서 처음 도입 되었고, 기존의 시스템에 비해 보다 효율적으로 데이터를 저장하고, 보관하며, 대용량 파일에 대응할 수 있도록 개발되었다.
(1). NTFS 시스템의 특징
① 데이터 복구 기능 : 신뢰성을 높이기 위해 모든 작업을 기록하고, 문제 발생시 기록을 토대로 복원하는 기능을 탑재하였음.
② 암호화
③ 압축 : LZ77의 변형된 알고리즘을 통해 파일 시스템 수준에서 압축
④ ADS(Alternate Data Stream) 저장 기능
⑤ 대용량 지원 : 이론상 264 Bytes까지 가능하나, 실제로 244 Bytes(16TB)까지 지원.
(2). MBR vs NTFS
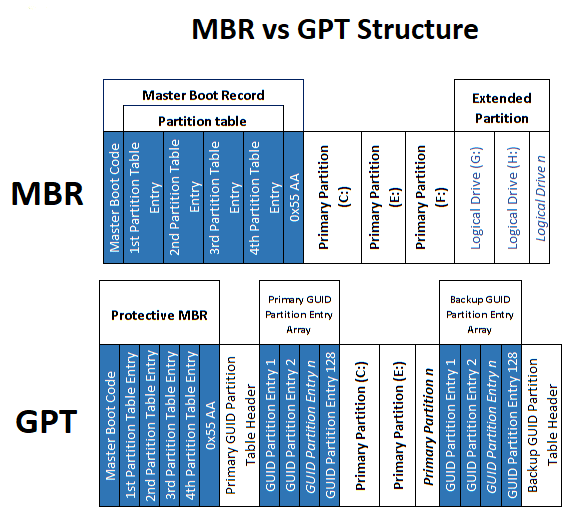
그림 1-1은 MBR과 GPT의 구조 차이를 나타낸 것이다. MBR의 경우 데이터의 처음 부분에 Master Boot Record와 Partition Entry를 가지고 있고, 뒤에 데이터들을 가지고 있는 구조이다. GPT의 경우, 데이터손실 발생시 복원을 고려하여 BackUp data를 고려한 설계를 한 것이 다른 점이다. Protective MBR 뒤에 최대 128개의 Entry 공간이 있고, 각 파티션이 따라온 다음, 데이터를 끝내기 전에 다시 엔트리 정보와 헤더가 있어서 한쪽에 손실이 발생하더라도 데이터를 보존할 수 있다.
(3). GPT system의 파티션 데이터
아래의 그림 2를 참고하여 데이터 구간별로 부여된 기능에 대해 확인해 볼 수 있다. 1.2에서 언급한 것처럼, GPT는 Primary GPT와 Secondary GPT를 가지고 있는데, 이는 한쪽에서 손실이 발생하더라도 데이터를 보존하기 위함인데, 왼쪽에 음수로 표시된 부분은 맨 끝에서 거꾸로 구조가 시작되는 것을 의미한다. LBA는 논리 블록 주소 지정(Logical block addressing)이라는 것인데, 컴퓨터 기억 장치에 저장되는 데이터 블록의 위치를 지정하는데 쓰이는 용어이다. 여기서는 512 Bytes 단위로 사용된다. 데이터의 표기는 Little Endian 방식을 사용한다.
Byte 표기법에는 Big Endian과 Little Endian이 있다. 10진수로 123456을 표기하고자 할때, 16진수로는 0x1 E2 40로 표기할 수 있는데, 이 표기가 Big Endian이다. (설명을 위해 두 자리씩 띄어서 숫자를 표기하였다.) Little Endian은 가장 낮은 자리부터 두 자리씩 끊어서 구분한 다음 이를 역순으로 표기하는 것이 Little Endian이다. 그래서 위의 수를 Little Endian으로 표기하는 경우 이는 0x40 E2 01가 된다. 그래서 2 Bytes이상의 데이터를 읽어올 때 숫자로 변환해야 하는 경우에는 표기법이 Little Endian이기 때문에 마찬가지로 Int.from_bytes(data, byteorder=’little’) 이라는 함수를 사용하여 올바르게 변환하도록 해야 한다.
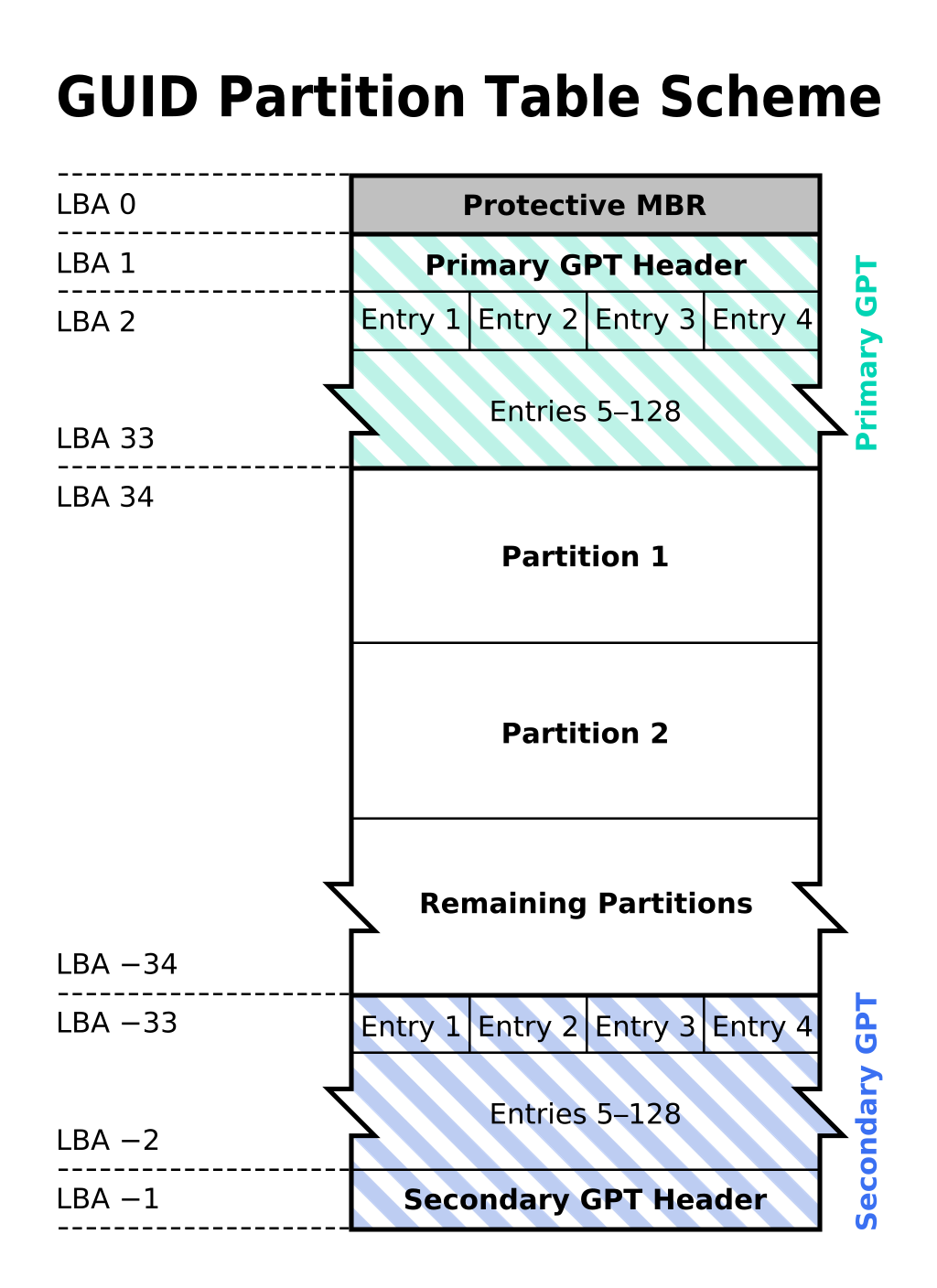
(3)-1. LBA 0
Pretective MBR 이라고 한다. 일반 MBR에서 실수로 데이터를 변경하지 않도록 Offset 0x1C2 자리에 b’\xEE’라고 표기하여 사용중임을 표시하고, 나머지 대부분의 자리는 비워둔다. Offset 0x1FE~0x1FF 자리에 signature인 b’\x55\xAA’를 기록한다.
(3)-2. LBA 1
실질적인 GPT Header 역할을 한다.
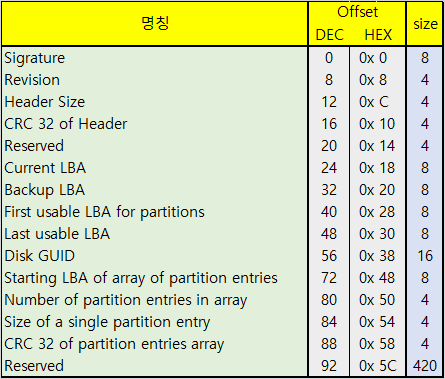

위의 <표 1>을 바탕으로 <그림 1-3>의 데이터를 해석하면 다음과 같은 내용을 얻을 수 있다.
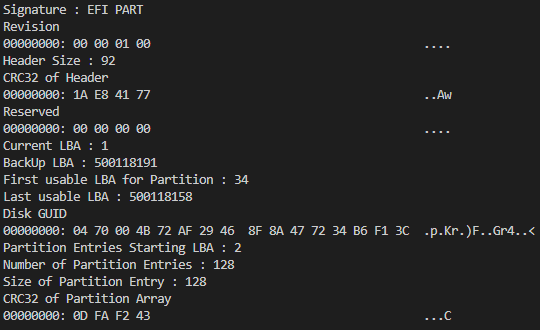
우선 Signature를 통해 본 시스템이 UEFI에 바탕을 둔 시스템인 것을 확인하였다. 해당 data가 있는 위치가 LBA 1 인 것이 표시 되어있고, Partition Entry가 LBA 2에서 시작하는 것과, Entry의 최대 개수, 각 Entry의 크기가 각각 128개, 128 Bytes 임을 확인 할 수 있다. Entry의 크기와 위치, 최대 개수를 확인 하였으니, LBA 2로 이동하여 Entry에 들어있는 데이터를 확인할 수 있다.
(3)-3. LBA 2 ~ 33
앞서 확인했던 LBA 1의 그림 4에서 얻은 정보를 계산해 보면, 각 Entry의 크기는 128 Bytes 이므로, 각 LBA 는 4개의 Entry를 가진다. 그러므로 128개의 Entry에 할당된 LBA는 32개 이다. 기존의 정보를 통해 LBA 2번부터 33번까지는 Partition Entry 0번부터 127번까지에 할당되어 있는 것을 확인 하였다.
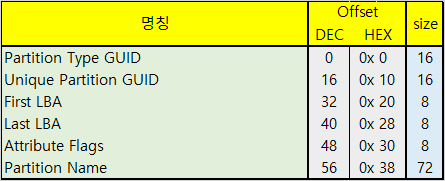
위의 <표 2>를 통해 각 Entry의 Data에 대해 확인할 수 있다.
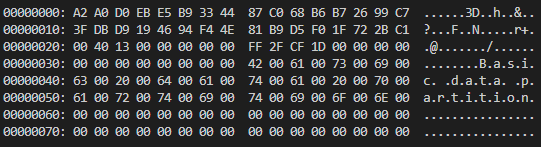
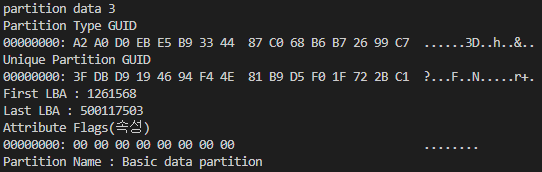
<그림 1-6>을 통해 First LBA를 확인 했는데, 이는 해당 파티션이 시작되는 위치이다. 각 파티션은 각자에 할당된 구간의 LBA를 사용하는데, Partition 3는 LBA 1261568 ~ 500117503을 할당 받아 사용한다. 현재 Partition 3를 C 드라이브로 사용하고 있고, 해당 드라이브 내부의 자료를 확인하기 위해 LBA 1261568로 이동해야 한다.
(4). 참고 사항
하드디스크 정보에 접근하기 위해 사용한 방법들
(4)-1. WinHex 프로그램
WinHex프로그램은 독일의 X – Ways 사에서 만든 프로그램으로 컴퓨터 포렌식과 소프트웨어 데이터 복구의 기능을 가진 Hex Editor 및 Disk Editor이다. 22년 11월 15일 기준으로 WinHex 20.7 버전이 출시되어 있다. 현재는 가로 한줄에 32 Bytes씩 표시해주고 있다.
Winhex.exe의 실행 시 관리자 권한으로 실행을 해야 하드디스크 정보에 접속할 수 있는 권한이 생긴다. 실행 후 상단 메뉴에서 Tools – Open Disk로 원하는 정보를 확인할 수 있으며, Physical Storage Devices 중에서 실행하게 되면, 상단의 파티션들을 더블클릭하여 해당 Logical Volume만 따로 확인하는 기능도 지원하고 있다.
(4)-2. VS Code를 통한 HDD 접근 방법
VS Code를 통해서 접근하는 과정에도 관리자 권한이 필요하다. 프로그램 실행할 때 관리자 권한으로 실행해야 내부의 바이너리 데이터를 확인할 수 있다.
(4)-3. Hexdump
HexDump는 Python 3에서 사용할 수 있는 라이브러리 중 하나이다. 처음 사용할때는 !pip install hexdump 라는 명령어를 사용하여 설치한 다음, 코드 안에서 import를 하여 사용한다.
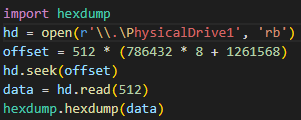
위의 예시에서 변수 data는 16진수 형태의 바이너리파일로, 위의 예시처럼 hexdump.hexdump() 로 함수를 불러서 함수 안에 바이너리 데이터를 입력하면 아래의 <그림 1-8>과 같이 출력된다

(4)-4. 사용한 기본 함수들
① Open( ) 하드디스크의 정보를 불러오는데 사용하였다. 바이너리 데이터로 불러오기 위해, reading + binary를 합쳐 ‘rb’라고 표기하여 정보를 불러온다.
② Seek( ) read()에서 자료를 읽기 위해, 자료의 시작지점을 입력하는 함수이다.
③ Read( ) 입력받은 숫자만큼의 데이터를 읽는 함수로, 최소 단위로 1개 LBA(512 Bytes)가 적절하여 512를 입력하여 사용하였다.
④ Chr( ) 출력하고자 하는 결과가 이름인 경우, 입력받은 값들을 ASCII 등으로 바꾸기 위해 사용하였다.
⑤ Join( ) Chr( )로 문자로 바꾼 것들을 한 문자열로 합치기 위해 사용하였다.
⑥ Int.from_bytes( data, byteorder=’little’) data 자리에 바이트 값을 입력하면 이를 Little Endian으로 계산하여 정수로 출력해주는 함수이다. 다만, 이를 위해 슬라이싱 인덱스를 사용할 때 주의해야 할점은, 구간이 아니라 특정 자리를 지정할 경우 Byte type이 아니라 Int type으로 출력된다는 점이다. Data[5:6]은 1자리의 Byte type이 출력되지만, Data[5]의 경우 Int Type이 출력되기 때문에, Type Error를 유발하게 된다.